
Building the tech behind Candor Studios's Project Dawnstone
While I've already written about the impact of Project Dawnstone on the service industry, I wanted to take a moment to dive into the technical details behind the project. If you haven't read about the project itself, I recommend you check it out first. Over the last year, I've been working closely with Candor Studios to develop the platform that powers Project Dawnstone while ensuring compatibility with their existing infrastructure.
The Tech Stack
The very fundamentals of the tech stack are generally pretty swappable, but here's what we used for Project Dawnstone:
- SvelteKit: powers the frontend of the platform, providing a fast and responsive experience for users.
- Java: was used for the backend of the platform, handling the syncing between the Candor Hub platform and Discord, which matches their existing infrastructure.
- Google Cloud: was used for hosting and managing the backend instances, as well as for the Pub/Sub system that allows instances to communicate with each other. These technologies were chosen for their reliability, scalability, and ease of use, allowing us to focus on building the platform itself rather than worrying about the underlying infrastructure.
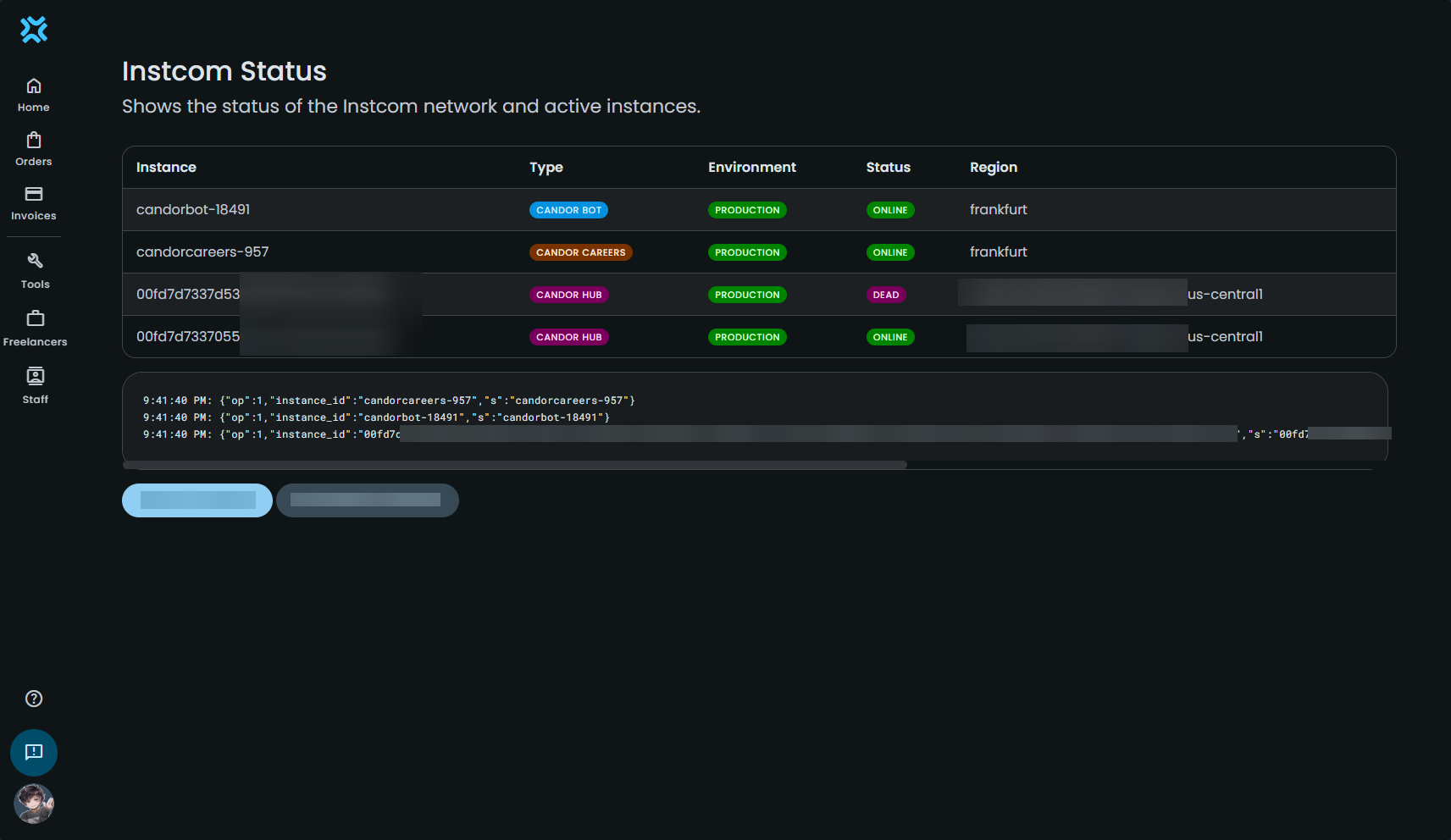
Instcom
Instcom is one of the key components that made this project possible, and one of the most complex (and generally tedious!) to develop. It's a custom system that I built to allow the backend instances and Discord bots to communicate with each other in real-time, keeping each other up to date with the latest information. This system is crucial for ensuring that messages are fully synced between the Candor Hub platform and Discord, providing a seamless experience for users on both ends.
How Instcom Works
Instcom is built on top of Google Cloud's Pub/Sub system which handles the real-time communication. It doesn't provide anything above that, so Instcom is the layer and protocol that sits on top.
Status Self-report
Whenever an instance starts up, it creates a subscription for itself under the central topic. While this is time consuming (it takes a few seconds), it's a necessary step to achieve many-to-many communication with Pub/Sub. Once it's subscribed, it can start sending and receiving messages. It starts by generating an instance object for itself and then announcing its presence to the other instances. This will look somewhat like the following:
{
"op": 0,
"instance": {
"id": "candorbot-1",
"status": 2,
"type": 0,
"environment": 0,
"version": "1.0.0",
"region": "us-central1"
}
}
Breaking this down,
opis the operation code, where0is the Status Self-report operation.instanceis the instance object, containing the instance's information.idis the instance's unique identifier, randomly generated.statusis the instance's status, where2is Online,1is Dead (not responding to requests but hasn't reported offline), and0is Offline.typeis the instance's type, where0is CandorBot,1is CandorHub, and2is CandorCareers. These are the only available types at the moment.environmentis the instance's environment, where0is Production,1is Staging, and2is Development.versionis the instance's version.regionis the instance's region.
This message is also sent whenever the status of the instance changes, such as when it goes offline or when it's restarted. When an op 0 message is received, all other instances will respond with their own op 0 message, ensuring that all instances are aware of each other's status. So when an instance comes online, it'll look something like the following:
- candorbot-1 comes online.
- candorhub-1 receives the message and responds with its own op 0 message.
- candorbot-2 receives the message and responds with its own op 0 message.
- candorcareers-1 receives the message and responds with its own op 0 message.
- candorbot-1 updates its list of instances to include candorhub-1, candorbot-2, and candorcareers-1.
This ensures that all instances are aware of each other's status and can communicate with each other as needed.
Heartbeating
To ensure that instances are still alive, they send a heartbeat message every x seconds. This message is a simple message with the operation code 1 and the instance's ID, like so:
{
"op": 1,
"instance_id": "candorbot-1"
}
If an instance has just come online, it waits to receive a heartbeat message before sending its own. This ensures they're all in sync and heartbeating at the same time. If an instance misses multiple heartbeats (an agreed upon number), it's marked as dead among all other instances, and they'll stop requesting things from it until it comes back online.
If an instance notices that its own heartbeat has failed for whatever reason, when it can send messages again, it must send an op 0 message to update its status to online. It will treat itself as dead until it does so.
Events & Messaging
All functional messages are op code 4. These messages are used for the application level, such as when a new order is created, when a quote is sent, or when a message is received from Discord. There are many different types of messages, and they all have their own structure and payloads.
Instcom messages can also act like requests and can be responded to. They're not all listed here, but here's an example of what a message (requesting a freelancer's profile from another instance) might look like:
{
"op": 4,
"name": "REQUEST_FREELANCER_PROFILE",
"data": {
"user_id": "freelancer-1"
},
"to": "candorbot-1",
"nonce": "1234567890",
"s": "candorhub-1",
"response": false,
"broadcast": false
}
Breaking this down,
opis the operation code, where4is the Events & Messaging operation.nameis the name of the event, in this case, REQUEST_FREELANCER_PROFILE.datais the data payload for the event, in this case, the user ID of the freelancer.tois the instance ID that the message is being sent to.nonceis a unique identifier for the message.sis the instance ID of the sender.responseis a boolean indicating whether this message is a response to another message.broadcastis a boolean indicating whether this message should be broadcast to all instances. If so,tois ignored. This is usually used for events that all instances need to know about.
This message would be sent from candorhub-1 to candorbot-1, requesting the profile of freelancer-1. candorbot-1 would then respond with the profile information, and candorhub-1 would handle it accordingly.
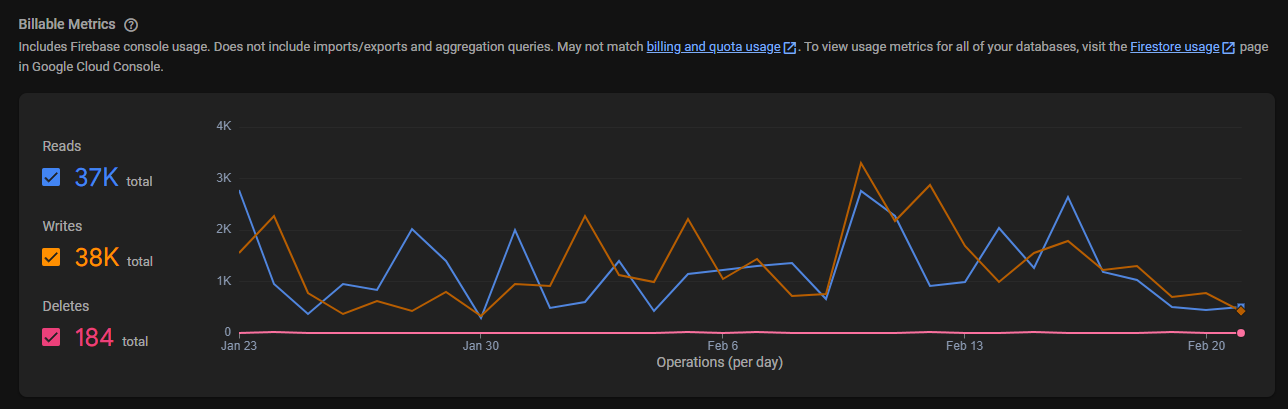
Firestore
Firestore is used for storing all the data that the platform needs, such as orders, quotes, messages, and user information. It's a NoSQL database that's perfect for this kind of application, providing fast and scalable storage for all the data we need to manage.
Part of the change to Candor Studios' new infrastructure meant we had to do huge amounts of data migration from their existing databases and files to Firestore. This was a complex process that required careful planning and execution to ensure that no data was lost or corrupted in the process.
Essentially, all new objects are created in Firestore. Then, if an object is found in the old system and retrieved at any point, it's migrated to Firestore. When retrieving an object, we check both systems unless we know it's only in Firestore (we have a list of these objects). It's fairly complex, but does the job well. We've managed to migrate around 10,000 objects using it!
Caching
Caching is also a big part of the move. Much of the existing infrastructure didn't care for caches as data was quick and free to access. Now, we have to be careful with how we cache data, as Firestore costs can add up quickly if we're not careful. We've implemented a caching system that's been working well so far, but it's something we're keeping an eye on as we scale up. This caching system was relatively complex as well, but only because it uses a lot of Java reflection to make it nice and flexible.
Backend Instances
CandorBot
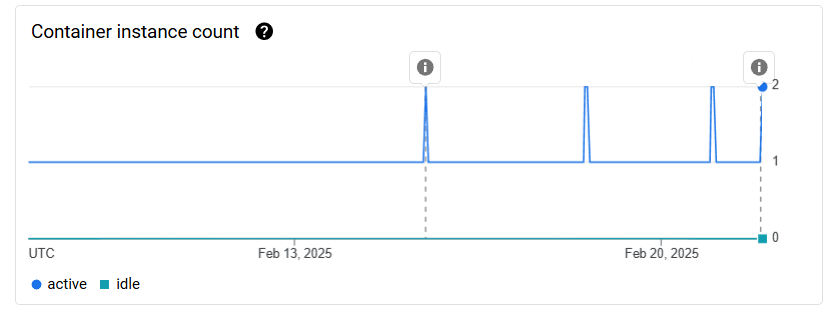
CandorBot, an existing and essential part of Candor Studios' infrastructure, is a Discord bot that handles all the communication between the Candor Hub platform and Discord. Part of this implementation was migrating CandorBot to Google Cloud Compute Engine instances.
CandorBot used to run on a single VPS, but as the platform grew, it became clear that this wasn't going to be sustainable in the long term. The VPS had regular downtime and it was causing a large amount of stress for the team. By moving CandorBot to Google Cloud, we were able to take advantage of the incredible reliability, and since moving, we've had next to no downtime whatsoever.
CandorBot now runs comfortably on an e2-medium instance, which provides just the right amount of resources for the bot to run smoothly without being too expensive.
Candor Hub
Candor Hub has its own backend which we decided to run on Google Cloud Run for its ease of use and scalability. It's also built in Java, with a combination of Spring and a custom framework I built for this project.
Running on Cloud Run has been a new experience for me, and it did take a little while to get working correctly. But once it was up and running, it's been smooth sailing. We decided to run with a minimum of 1 instance to remove cold starts, and we can always scale up if needed. This is relatively expensive, but Candor decided that is was worth the cost.
Frontend
The frontend of the platform was created using SvelteKit, an amazing framework that has been my go-to for a while now, primarily for the developer experience. The project involved building a new promotional page for Candor, as well as the platform itself. We designed everything using Figma, basing off Material Design and Candor's existing branding (which was recently updated by an external agency).
The frontend is hosted using Firebase Hosting, which has been a breeze to work with. It's fast, reliable, and easy to deploy to, making it the perfect choice for this project. Overall, the frontend has been a joy to work on, and I'm really happy with how it turned out.
Conclusion
Building the tech behind this project has been an incredible journey, taking over a year to complete (we started Nov 2023!). I've learned so much about Google Cloud and Java, and it's one of the largest solo software projects I've ever undertaken. Working with Candor Studios has been a fantastic experience, and I'm excited to see the impact that Project Dawnstone has on the industry as a whole.